1. 精确度、召回率、准确率
- 精确度(precision):又叫查准率,预测为正例的样本中,有多少比例是真正的正例。
-
召回率(recall):又叫查全率,真正的正样本中,有多少比例是预测对了。
-
准确率(accuracy):正确预测的比例 也就是有百分之几的样本被正确的分类了,(包括正、负样本)。
- 计算公式:
| - | P(真正) | N(真正) |
|---|---|---|
| P(预测) | TP | FP |
| N(预测) | FN | TN |
真阳性(TP)——正确的肯定 真阴性(TN)——正确的否定 假阳性(FP)——错误的肯定,假报警,第一类错误 假阴性(FN)——错误的否定,未命中,第二类错误
精确度:(precision) 精确度P:
召回率:(recall)
- $F1-measure$
$F1-measure$计算公式如下:
2. PR曲线和ROC曲线
-
如何得到PR曲线? 对于一些模型(e.g. Logistic Regression、SVM、神经网络)输出一个得分score。将score从大到小排序,依次以每个score为阈值,预测样本的正负,得到分类结果,然后计算precision和recall。 假设测试集有200个样本,那么就可以得到200个precision-recall,以precision为x轴,recall为y轴就可以在二维坐标图中得到PR曲线。
-
如何得到ROC曲线? 方法和上面的类似,只是x轴是假阳性率, y轴是真阳性率 sklearn中的ROC
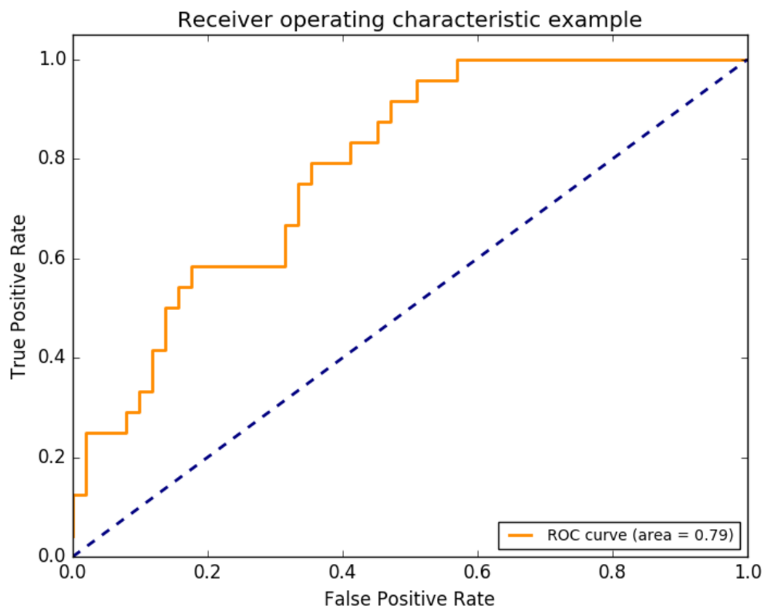
- 为什么用ROC曲线?
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。