1. 标准的神经网络
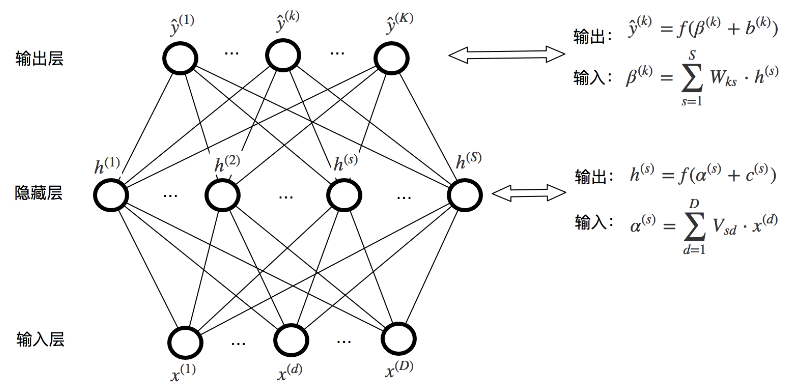
神经单元上的非线性映射函数 $f$ 是 $sigmoid$ 函数:
$sigmoid$ 函数的导函数很有特点:
2. 推导过程
2.1 $Loss \, Function$
-
$Loss \, Function$:
-
样本 $(x_i, y_i)$ 在模型上的均方误差为: 注意:$y_i^{(k)}$中的$k$是指第$k$个输出单元,并不是指$k$次方
2.2 权值的梯度
- 误差从输出层反传到隐层,推导$\nabla W_{ks}$
- 误差从隐层反传到输入层,推导$\nabla V_{sd}$
2.3 $bias$ 的梯度
-
输出层的$\nabla bias$
-
隐藏层的$\nabla bias$
3. 伪代码(用梯度下降法)
梯度下降算法训练神经网络:

4. SGD
为了解决梯度下降算法训练样本输入数据太大,学习速度太慢的问题,产生了一种新的算法叫做随机梯度下降算法 $Stochastic \;\; Gradient \,\, Descent$ 。 随机选取的m个输入样本, ${ x_1, x_2,…, x_m }$ 称作 $mini-batch$ 。
- 梯度下降和SGD的区别:
–标准梯度下降是在权值更新前对所有样例汇总误差,而随机梯度下降的权值是通过考查某个训练样例来更新的
–在标准梯度下降中,权值更新的每一步对多个样例求和,需要更多的计算
–标准梯度下降,由于使用真正的梯度,标准梯度下降对于每一次权值更新经常使用比随机梯度下降大的步长
–如果标准误差曲面有多个局部极小值,随机梯度下降有时可能避免陷入这些局部极小值中
5. 向量化表示
为了实现神经网络方便,我们将其参数用矩阵或者向量表示。
5.1. 基础
黑体表示矢量或者矩阵,非黑体表示标量。假设当前层是 $l$,那么输入向量是:$\boldsymbol{z}^l$
输出向量是:$ \boldsymbol{a}^l $
5.2. 推导
神经网络的损失在 $l$ 层上的传播误差向量化形式为:
当 $l=L$ 时候,
当 $l \not = L$ 时候,
- 对参数 $\boldsymbol{W} $ 的偏导数:
由于 $J$ 对 $w_{ij}^l$的导数为:
所以,总的损失对 $l$ 层的权重矩阵的偏导数为:
- 对 $ \boldsymbol{b} $ 的偏导数:
由于 $J$ 对 $b_{i}^l$的导数为:
所以,$J$ 对 $\boldsymbol{b}^l$的偏导数为: